Felix Pinkston
Jul 15, 2024 18:56
Anyscale launches Replica Compaction to address resource fragmentation, enhancing resource utilization and reducing costs for Ray Serve deployments.
Companies embracing AI are increasingly facing the issue of resource utilization and cost management. Model serving and inference in particular need to be able to scale up and down over time in response to traffic. Ray Serve is a scalable model serving library built on Ray to help handle these dynamics. And while open source systems like Ray Serve help manage increased traffic, even sophisticated systems struggle to scale down once traffic abates. This type of resource fragmentation inevitably leads to underutilized resources and higher costs.
Anyscale’s new Replica Compaction feature helps to solve resource fragmentation by optimizing resource usage for online inference and model serving. Take a look at how this feature works, as well as how you can use it in practice.
Background: What is Ray Serve?
Ray Serve has several key concepts:
-
Deployment: A deployment contains business logic or an ML model to handle incoming requests.
-
Replica: A replica is an instance of a deployment that can handle requests. These are implemented with Ray Actors. The number of replicas can be scaled up or down (or even autoscaled) to match the incoming request load.
-
Application: An application is the unit of upgrade in a Ray Serve cluster. An application consists of one or more deployments.
-
Service: A Service is a Ray Serve cluster that can consist of one or more applications.
Deployments handle incoming requests independently which allows for parallel processing and efficient resource utilization in most cases. For example, Ray Serve makes it possible to create deployments for Llama-3-8B and Llama-3-70B on the same Service with different resource requirements (1 GPU and 4 GPU per replica respectively). Both of these deployments would scale independently in response to their respective traffic.
The Problem of Resource Fragmentation
Resource fragmentation occurs when scaling activities lead to uneven resource utilization across nodes. As replicas increase, the autoscaler will start new nodes to handle the increased deployment load. But then, when traffic decreases and models scale down, the same nodes that were needed to handle the increased load become underutilized. This is one of the most common reasons for increased costs and reduced cluster performance.
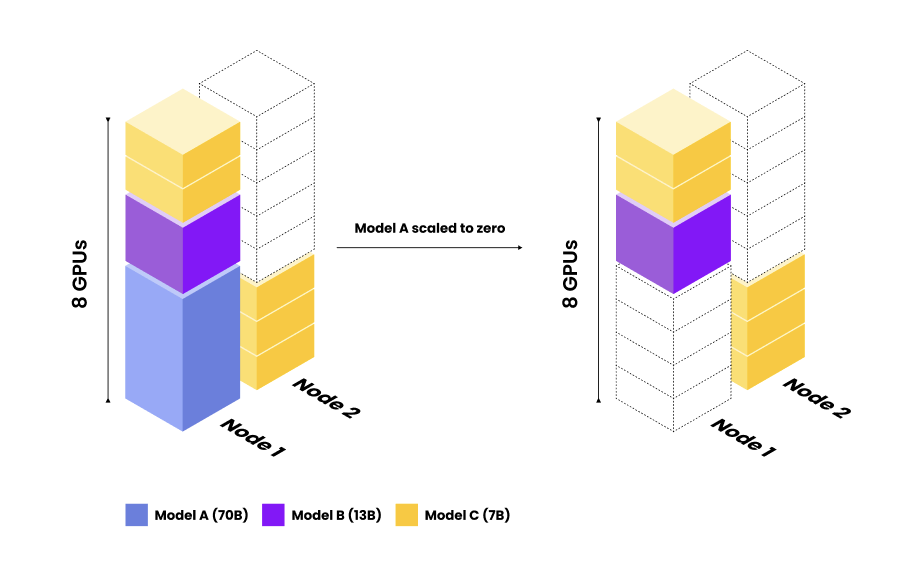
Essentially, when scaling a specific deployment or model (e.g. Model A), Ray Serve takes into account the traffic and resource requirements for that particular deployment alone. The state, replicas, and traffic of any other deployments (e.g. Models B and C) are not taken into account during the scaling process. Because scaling only considers a single deployment at a time, resource fragmentation is inevitable as traffic changes and the cluster scales up and down.
Solving the Resource Fragmentation Issue with Anyscale’s Replica Compaction
Anyscale introduces Replica Compaction to address resource fragmentation. With Replica Compaction, Anyscale will automatically migrate replicas into fewer nodes in order to optimize resource use and reduce costs. There are three main components to the Replica Compaction feature:
-
Replica Migration: Compaction monitors the cluster for opportunities to migrate replicas. If a node is minimally used, Anyscale’s Replica Compaction will automatically move replicas to other nodes with sufficient capacity. Every node in the cluster is checked and nodes with fewer replicas that can be released are prioritized.
-
Zero Downtime: Migration is effortless. Anyscale Services seamlessly spins up a new replica, monitors its health, reroutes traffic, and removes the old replica.
-
Autoscaler Integration: The Anyscale Autoscaler continuously searches for idle nodes post-migration and spins them down as needed, reducing node count—and costs.
Let’s take a look at our same example from above, now with Anyscale’s Replica Compaction. With Replica Compaction, Anyscale is able to detect when Model A is downscaled, and it automatically migrates the excess Model C replicas into a single node.

Example of Anyscale Replica Compaction. Anyscale Replica Compaction detects resource fragmentation is causing unnecessary resource usage. The replicas are automagically shifted (without interrupting production traffic) to a single node, thereby reducing costs and boosting utilization.
Replica Compaction in Action: Practical Results
To test the new Replica Compaction feature, Anyscale ran a live production workload for several months. Take a look at what was run—and how Replica Compaction decreased cost and increased efficiency.
Case Study:
Anyscale offers a serverless API to prompt LLMs including Mistral, Mixtral, Llama3, and more. These models are deployed as replicas in an Anyscale Service. This service has been running for several months, serving 10+ models to users at scale with widely varying traffic patterns.
After releasing Anyscale Replica Compaction, significant savings and efficiency improvements were found looking at tokens per GPU second. With no other changes (i.e. changing the tensor parallelism or models being served and hardware used), the overall efficiency improvement post Replica Compaction was ~10% on average. Overall, in the immediate day after enabling, instance seconds declined 3.7%, despite traffic, measured by # tokens, increasing by 11.2% in the same period. Since high-end GPUs like A100s and H100s are used for serving models, this translates to substantial cost savings.
The impact and savings from Replica Compaction vary widely depending on the distribution of traffic, number of deployments, and underlying instances. In less scaled scenarios, costs can be reduced by 50% (or more!).
What’s Next for Replica Compaction
The team is continuing to improve the Replica Compaction algorithm including work to factor in node costs and resource types to better optimize usage and overall costs. Stay tuned for more exciting updates in the coming months.
Get Started with Anyscale
Anyscale’s new Replica Compaction feature significantly improves resource management in distributed clusters by addressing resource fragmentation. This ensures an efficient, cost-effective infrastructure for Ray Serve deployments, with ongoing enhancements promising even smarter resource management. Anyscale Replica Compaction is configured by default for Ray Serve applications deployed on the Anyscale Platform.
Get started today!
Image source: Shutterstock
Credit: Source link